BUAA-OS-lab1

这一个lab的标题是内核、启动和printf,看得出相当的大杂烩。
内核和启动
这个lab要初步实现一个比较简易的操作系统。
Makefile
课程组给出了数量可观的代码,可以从顶层 Makefile 入手阅读。 Makefile 的作用在于方便增量编译和管理依赖关系。
55行前给出了一堆宏,通过这些宏可以实现配置QEMU模拟器参数和根据实验进度调整编译配置。从lab2到视角回看需要注意以下几个宏:
link_script := kernel.lds: 指定链接脚本,决定内核代码在内存中的具体布局modules := lib init kern: 源码目录列表,意味是内核的核心代码分布在lib(库函数)、init(初始化代码)和kern(内核核心逻辑)这三个子目录中targets := $(mos_elf): 定义这次编译任务最终要生成的目标文件objects := $(addsuffix /*.o, $(modules)) $(addsuffix /*.x, $(user_modules)): 汇合已经编译好的二进制目标文件(.o或.x).PHONY表明列在后面的东西不受make工具关于时间戳的约束,保证调用时被执行
为什么是从lab2视角呢,因为之前太懒了不想写博客拖到五一才动手💤。
55行后给出了具体的编译规则,大体可以分为递归编译 modules 列表里的文件、当所有子模块都编译完后调用链接器 $(LD) 和运行调试接口三部分。
放一张chatgpt生成的依赖关系图,仅供参考。
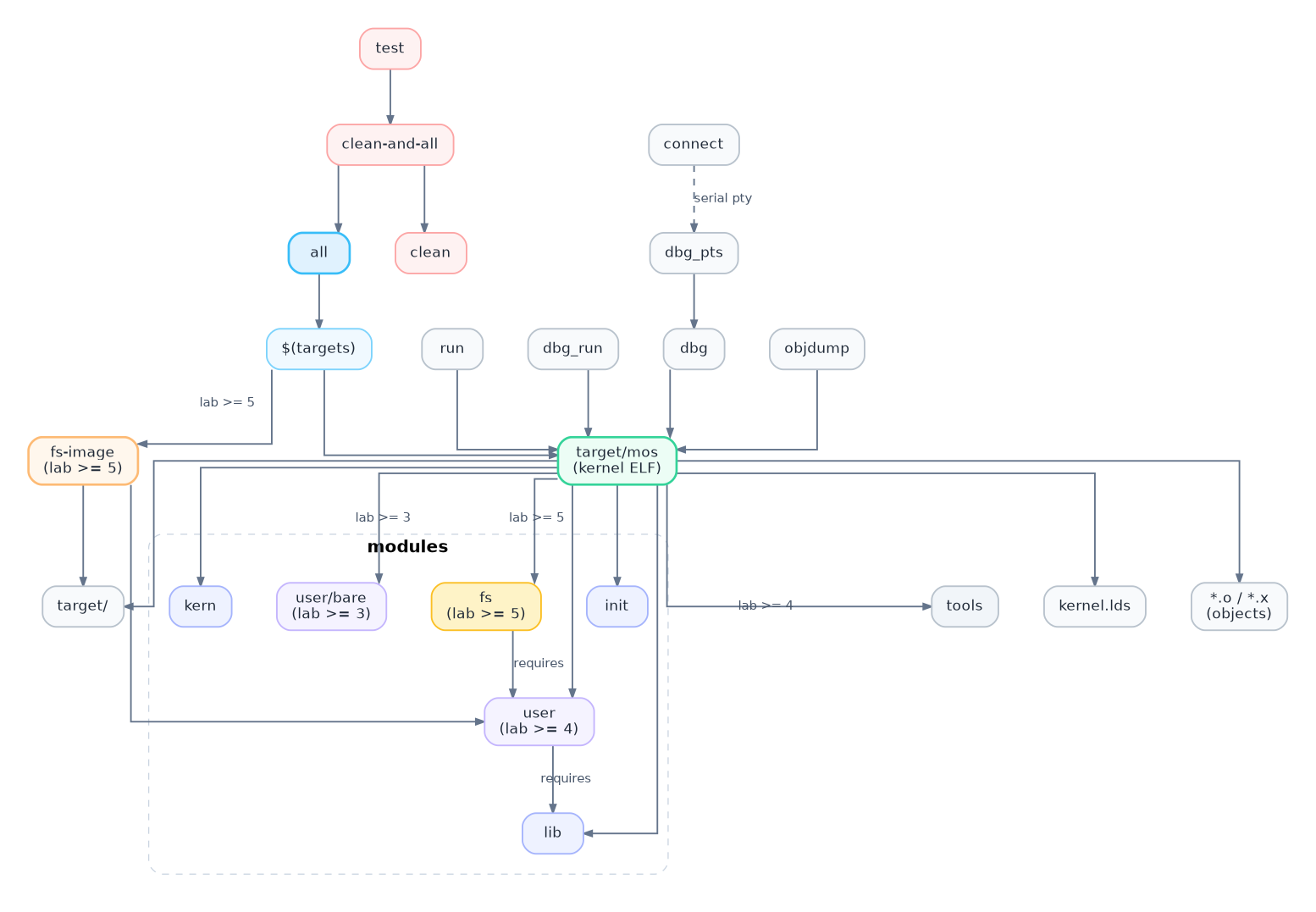
文件目录
init初始化内核,其中:start.S初始化CPU和栈指针,跳转到mips_init()函数init.c实现mips_init()函数,调用内核中各模块的初始化函数
include存放系统头文件lib存放常用库函数kern存放内核主体代码tests存放测试代码
ELF
ELF文件的解析是一个考点,换言之要知道相关结构体如何操作。这部分的内容都在 tools/elf/ 文件夹中,相关结构体定义在其中 elf.h 文件里。
elf.h 文件31~52行规定了一些字段的大小,接着58~119行定义 Elf32_Ehdr 用于存储ELF文件头, Elf32_Shdr 用于存储段头,Elf32_Phdr 用于存储节头,定义了魔数验证相关字段。
1 |
|
考点主要有从ELF头中找到节表头/某节/段表头/某段,打印对应的字段等等。以下以26exam代码为例。
Exam
题目要求输出:
- 该ELF文件总节数 ➡️ 读
Elf64_Ehdr结构体 .symtab节对应节头在节头表中下标 ➡️ 涉及字符串匹配- 每节名称、文件偏移
sh_offset和大小sh_size➡️ 读对应的Elf64_Shdr结构体
注意到 e_shstrndx 是节头字符串表在节头表中的索引,即 Elf32_Shdr 中的 sh_name 字段其实存储在 Section[e_shstrndx] 这一节头表对应的内存中,代码中为从 shstrtab 开始的一块内存。注意到 shstrtab 为 char* 类型,即以存储地址的大小为大小偏移,所以 sectionName = shstrtab + sh_table[i].sh_name 可以轻松得到存储节名的地址。
此处涉及字符串匹配,别忘了 strcmp 以及 string.h 里的一堆函数。
1 | int readelf64(const void *binary, size_t size) { |
MIPS内存布局
- kuseg 0x0000_0000~0x8fff_ffff
- kseg0 0x8000_0000~0x9fff_ffff
- kseg1 0xa000_0000~0xbfff_ffff
- kseg2 0xc000_0000~0xffff_ffff
将内核放在kseg0,bootloader在载入内核前会进行 cache 初始化工作,内核可以顺利加载。
Linker Script 中记录了各个节应该如何映射到段(控制了节放置的地址),由此可以控制链接器的链接过程。
.text .data .bss 从0x8002_0000开始放置。
modules :等待编译的源码文件夹,targets :编译得到的 .x 和 .o 文件。
_start 函数:清空bss段地址里的内容,将sp指针指向 0x8040_0000,跳转到 mips_init 函数。
printk
void printk(const char *fmt, ...)void: 函数不返回任何值。const char \*fmt: 这是一个字符串指针,指向“格式字符串”(例如"Value: %d\n")。...: 这是一个变长参数。它允许你在调用函数时传入任意数量、任意类型的参数。
va_list ap;定义一个名为ap的列表变量,用于存储变长参数的信息。va_start(ap, fmt);初始化ap。它告诉编译器:变长参数是从fmt之后开始的。vprintfmt(outputk, NULL, fmt, ap);vprintfmt: 这是一个通用的格式化引擎。它会扫描fmt字符串,每当遇到%(如%d,%s,%x)时,就从ap中取出一个参数进行转换。outputk: 这是一个回调函数。vprintfmt每处理好一个字符,就会调用outputk把这个字符发送到硬件设备。NULL: 观察到这里的NULL对应void outputk(void *data, const char *buf, size_t len)里的data,但代码里无论是outputk还是printcharc都没有用到它。
va_end(ap);清理并关闭ap列表。在某些架构上这可能只是简单的宏定义,但在编写健壮的代码时,它是规范要求的,能防止栈损坏。
Extra
26年extra要仿照 printk 完成新函数 scank 。本次的注释给得相当到位,堪称宝宝巴士。
本题需要精准实现标准格式控制符(
%c、%u、%s)对字符流的“吞吐行为”。 由于在解析变长数据(如读取数字和字符串)时,程序通常需要多读一个不属于该格式的字符才知道当前读取已经结束。因此,如何妥善保管这个“多读出来”的字符,不让它被丢弃,使得下一个格式符能继续正常解析,是本次实现的关键。
题中函数调用关系:
scankvscanfmtscan_cscan_sscan_u
此处放一下我的代码
1 | // kern/printk.c |
个人觉得这次的重点应该是区分 in 和 ensure_char 。